Unser Wissen
für Euch

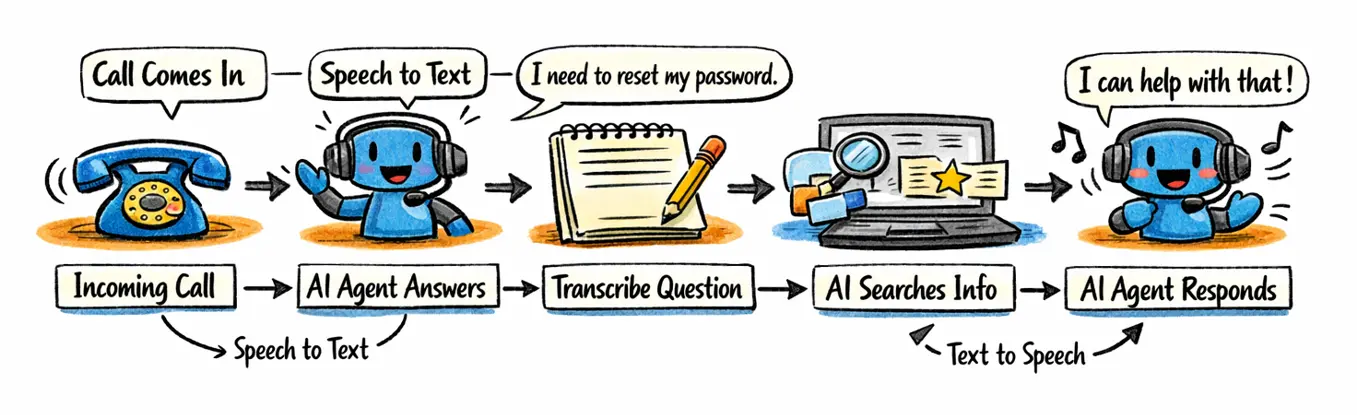
Wie funktioniert das mit der Sprache in Voice‑AI?
Speech‑to‑Text
Ist heute meist der erste Schritt in einer Voice‑AI‑Pipeline. Gesprochene Sprache wird in Text umgewandelt – erst so können KI‑Systeme Inhalte verstehen,
durchsuchen und weiterverarbeiten. Deshalb sind Transkripte die Basis für Funktionen wie Zusammenfassungen, Insights oder automatische Follow‑ups.
Text‑to‑Speech
Bildet das Gegenstück: KI‑Antworten werden wieder hörbar. Moderne TTS‑Modelle klingen dabei deutlich natürlicher als früher und lassen sich in Tonfall,
Geschwindigkeit und Betonung anpassen. Genau das macht sprachbasierte KI‑Antworten heute so zugänglich und „menschlich“.
Speech‑to‑Speech
Geht noch einen Schritt weiter und arbeitet direkt mit Audio – ganz ohne Zwischenschritt über Text. Das ermöglicht extrem schnelle Reaktionen und eine sehr gute Erfassung von Intonation. Der Nachteil: Für komplexes Reasoning oder präzise Anweisungen sind diese Modelle weniger zuverlässig. Sie eignen sich daher vor allem für einfache, schnelle Interaktionen.
Fazit
In der Praxis kombinieren die meisten Lösungen diese Ansätze: Sie setzen bewusst auf Genauigkeit, Kontrolle und Nachvollziehbarkeit – auch wenn das etwas langsamer ist als reine Speech‑to‑Speech‑Systeme. Genau hier entscheidet sich, ob Voice‑AI produktiv einsetzbar ist oder nicht.
Unser Wissen
für Euch
Wie funktioniert das mit der Sprache in Voice‑AI?
Speech‑to‑Text
Ist heute meist der erste Schritt in einer Voice‑AI‑Pipeline. Gesprochene Sprache wird in Text umgewandelt – erst so können KI‑Systeme Inhalte verstehen,
durchsuchen und weiterverarbeiten. Deshalb sind Transkripte die Basis für Funktionen wie Zusammenfassungen, Insights oder automatische Follow‑ups.
Text‑to‑Speech
Bildet das Gegenstück: KI‑Antworten werden wieder hörbar. Moderne TTS‑Modelle klingen dabei deutlich natürlicher als früher und lassen sich in Tonfall,
Geschwindigkeit und Betonung anpassen. Genau das macht sprachbasierte KI‑Antworten heute so zugänglich und „menschlich“.
Speech‑to‑Speech
Geht noch einen Schritt weiter und arbeitet direkt mit Audio – ganz ohne Zwischenschritt über Text. Das ermöglicht extrem schnelle Reaktionen und eine sehr gute Erfassung von Intonation. Der Nachteil: Für komplexes Reasoning oder präzise Anweisungen sind diese Modelle weniger zuverlässig. Sie eignen sich daher vor allem für einfache, schnelle Interaktionen.
Fazit
In der Praxis kombinieren die meisten Lösungen diese Ansätze: Sie setzen bewusst auf Genauigkeit, Kontrolle und Nachvollziehbarkeit – auch wenn das etwas langsamer ist als reine Speech‑to‑Speech‑Systeme. Genau hier entscheidet sich, ob Voice‑AI produktiv einsetzbar ist oder nicht.




